In the last article, we mentioned the metaphor of board games and the shortcomings of pure reinforcement learning technology (Stanford scholars think coldly: reinforcement learning has basic defects). In this part, we will enumerate some methods of adding prior knowledge, at the same time we will introduce deep learning, and show the investigation of recent results.
So, why not jump out of the circle of pure reinforcement learning?
You might think:
We cannot go beyond pure reinforcement learning to imitate human learning-pure reinforcement learning is a strictly formulated method, and the algorithms we use to train AI agents are based on this. Although learning from scratch is not as good as providing more information, we did not do that.
It is true that adding prior knowledge or task guidance will be more complicated than pure reinforcement learning in the strict sense, but in fact, we have a method that can guarantee learning from scratch and is closer to human learning.
First of all, let us clearly explain the difference between human learning and pure reinforcement learning. When we start to learn a new skill, we mainly do two things: guess what the general method of operation is, or explain it. From the very beginning, we understood the goal and general usage of this skill, and we never generated these things from the low-end reward signal.

Researchers at UC Berkeley have recently discovered that human learning is faster than pure reinforcement learning at certain times because humans use prior knowledge
Use prior knowledge and instructions
This idea has similar results in AI research:
The meta-learning method to solve "learning how to learn": Let the reinforcement learning agent learn a new technology more quickly. There are already similar skills, and learning how to learn is exactly the way we need to use prior knowledge to go beyond pure reinforcement learning.

MAML is an advanced meta-learning algorithm. The agent can learn to run forward and backward after a few iterations of meta-learning
Transfer learning: As the name suggests, it is to apply the method learned on one problem to another potential problem. Regarding transfer learning, DeepMind's CEO said so.
I think (transfer learning) is the key to strong artificial intelligence, and humans can use this skill skillfully. For example, I have played a lot of board games now. If someone teaches me another board game, I may not be so unfamiliar. I will apply the enlightening methods I learned in other games to this game. , But now machines can’t do it... so I think this is a major challenge for strong artificial intelligence.
Zero-shot learning: Its purpose is also to master new skills, but without any attempts of new skills, the agent only needs to receive "instructions" from the new task, and it can perform once even if the new task has not been performed. It's good.
One-shot learning and few-shot learning: These two types are popular areas of research. They are different from zero-shot learning because they will use the skills to be learned as a demonstration, or only require Few iterations.
Life long learning and self supervised learning: that is, learning without human guidance for a long time.
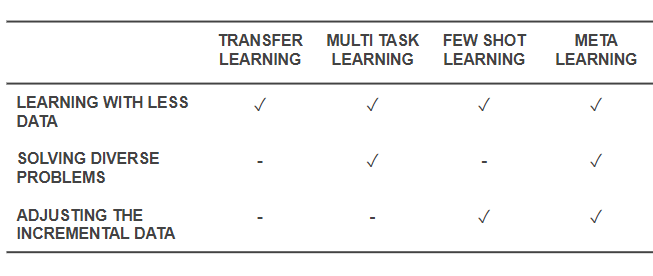
These are reinforcement learning methods other than learning from zero. In particular, meta-learning and zero-time learning reflect people's more likely practices when learning a new skill, which is different from pure reinforcement learning. A meta-learning agent will use prior knowledge to quickly learn board games, even though it does not understand the rules of the game. On the other hand, a zero learning agent will ask the rules of the game, but will not make any learning attempts. The one-time learning method is similar to the small-time learning method, but only knows how to use the skill, which means that the intelligent experience observes how other people play the game, but does not ask for an explanation of the game rules.

Recently, a method that mixes one-time learning and meta-learning. From One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning
The general concepts of meta-learning and zero-learning (or less-learning) are reasonable parts of board games. However, it is better to combine zero-learning (or less-learning) and meta-learning to be closer to humans The way to learn. They use prior experience, explanatory guidance, and trial and error to form initial assumptions about skills. After that, the agent personally tried this technique and relied on the reward signal for testing and fine-tuning, thus making a better skill than the initial hypothesis.
This also explains why pure reinforcement learning methods are still the mainstream, and research on meta-learning and zero-order learning has received little attention. Part of the reason may be that the basic concepts of reinforcement learning have not been questioned too much, and the concepts of meta-learning and zero-time learning have not been applied to the realization of basic principles on a large scale. Among all the researches that use reinforcement learning alternative methods, perhaps the one that best meets our hopes is the Universal Value Function Approximators proposed by DeepMind in 2015, in which Richard Sutton proposed the "general value function". The abstract of this paper is written like this:
The value function is the core element in the reinforcement learning system. The main idea is to establish a single function approximator V(s; θ), and estimate the long-term reward of any state s through the parameter θ. In this paper, we propose universal value function approximators (UVFAs) V(s, g;θ), which can not only generate the reward value of state s, but also the reward value of target g.
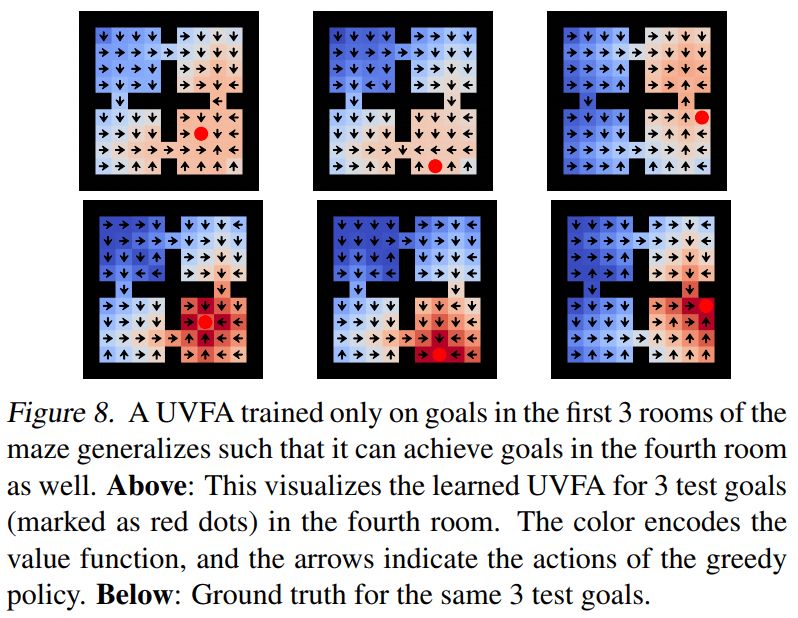
Apply UVFA to practice
This rigorous mathematical method regards the goal as the basic and necessary input. The agent is told what to do, just like in zero learning and human learning.
It has been three years since the paper was published, but only a few people are happy with the results of the paper (the author counts only 72 people). According to data from Google Scholar, the article Human-level control through deep RL published by DeepMind in the same year has received 2,906 citations; Mastering the game of Go with deep neural networks and tree search published in 2016 has received 2,882 citations.
Therefore, there are indeed researchers working towards combining meta-learning and zero-time learning, but according to the number of citations, this direction is still unclear. The key question is: Why don't people regard this combined method as the default method?
The answer is obvious, because it is too difficult. AI research tends to solve independent, well-defined problems in order to make better progress, so apart from pure reinforcement learning and learning from zero, few studies can do it because they are difficult to define. However, this answer does not seem satisfactory enough: deep learning allows researchers to create hybrid methods, such as models that include NLP and CV tasks, or the original AlphaGo adds deep learning and so on. In fact, DeepMind's recent paper Relational inductive biases, deep learning, and graph networks also mentioned this point:
We believe that the key way to strong artificial intelligence is to make combined generation as the first priority, and we support the use of multiple methods to achieve goals. Biology is not simply the opposite of nature and post-cultivation. It combines the two to create more effective results. We also believe that architecture and flexibility are not antagonistic, but complementary. Through some recent mixed cases of structure-based methods and deep learning, we have seen great prospects for combining technologies.
Recent meta-learning (or zero-learning) results
Now we can conclude:
Motivated by the metaphor of the board game in the previous article and the proposal of the DeepMind universal value function, we should reconsider the foundation of reinforcement learning, or at least pay more attention to this field.
Although the existing results are not popular, we can still find some exciting results:
Hindsight Experience Replay
Zero-shot Task Generalization with Multi-Task Deep Reinforcement Learning
Representation Learning for Grounded Spatial Reasoning
Deep Transfer in Reinforcement Learning by Language Grounding

Cross-Domain Perceptual Reward Functions
Learning Goal-Directed Behaviour
The above papers are a combination of various methods, or goal-oriented methods. What’s even more exciting is that there are some recent works that have studied instinctive motivation and curiosity-driven learning methods:
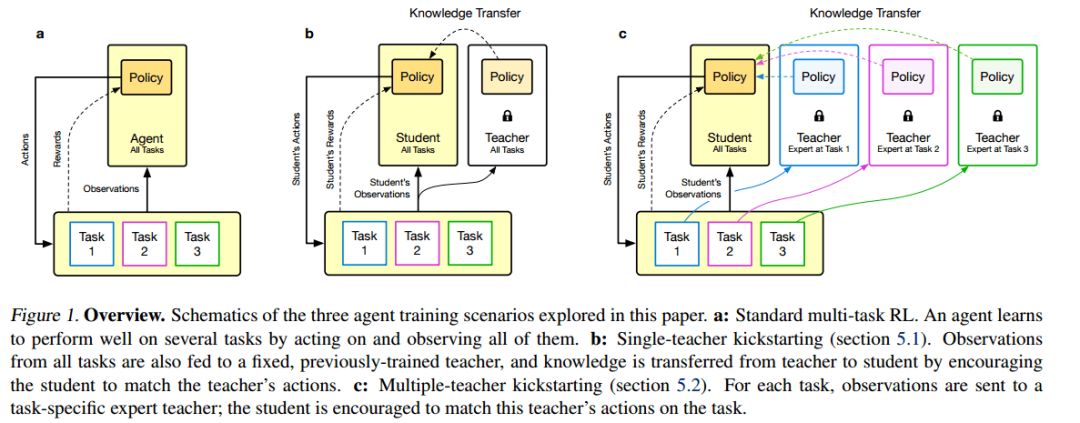
Kickstarting Deep Reinforcement Learning
Surprise-Based Intrinsic Motivation for Deep Reinforcement Learning
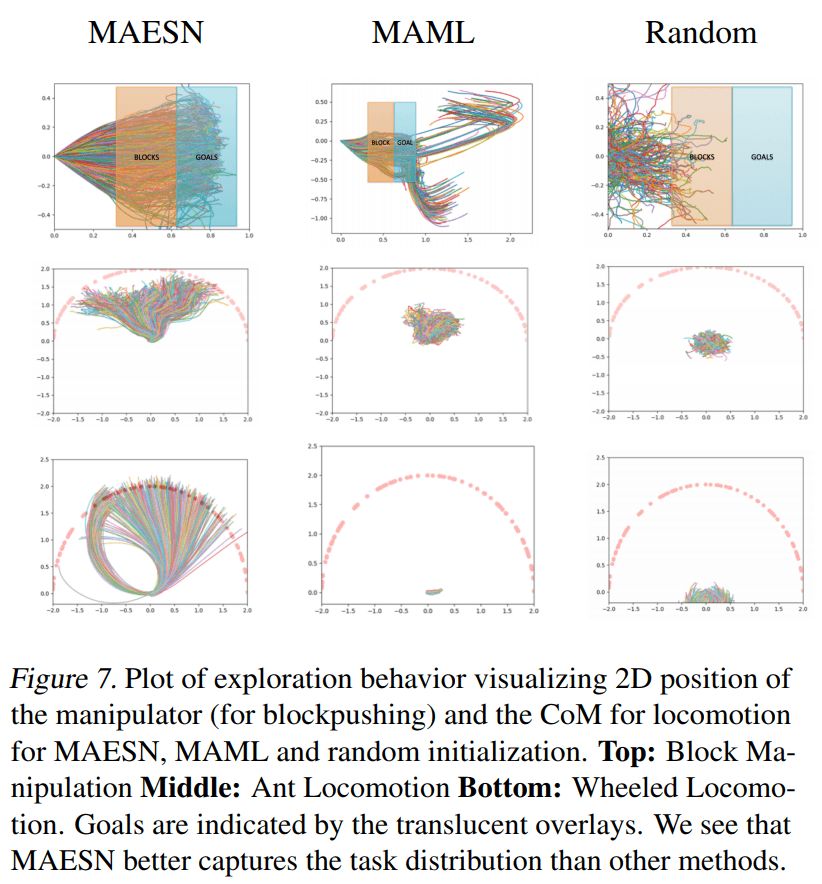
Meta-Reinforcement Learning of Structured Exploration Strategies
Learning Robust Rewards with Adversarial Inverse Reinforcement Learning
Curiosity-driven Exploration by Self-supervised Prediction
Learning by Playing-Solving Sparse Reward Tasks from Scratch
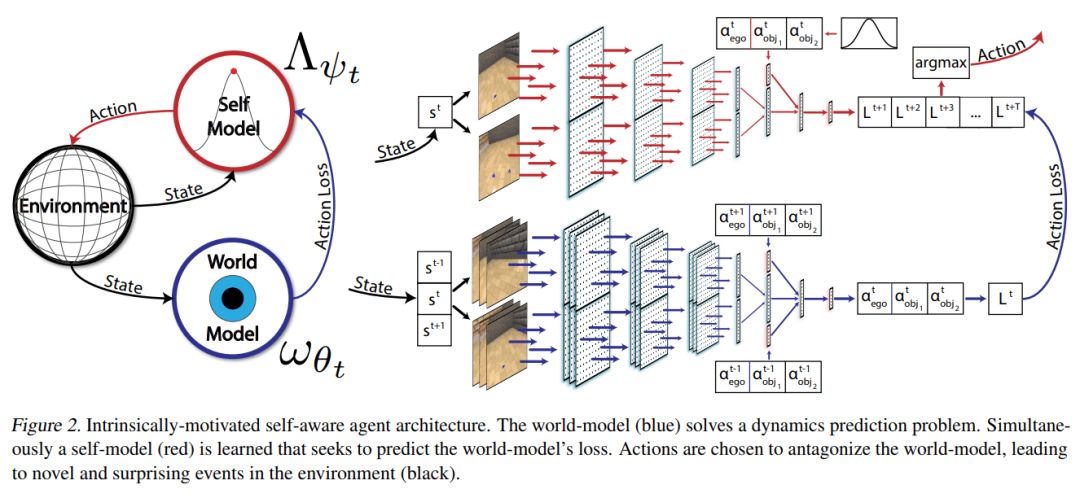
Learning to Play with Intrinsically-Motivated Self-Aware Agents
Unsupervised Predictive Memory in a Goal-Directed Agent
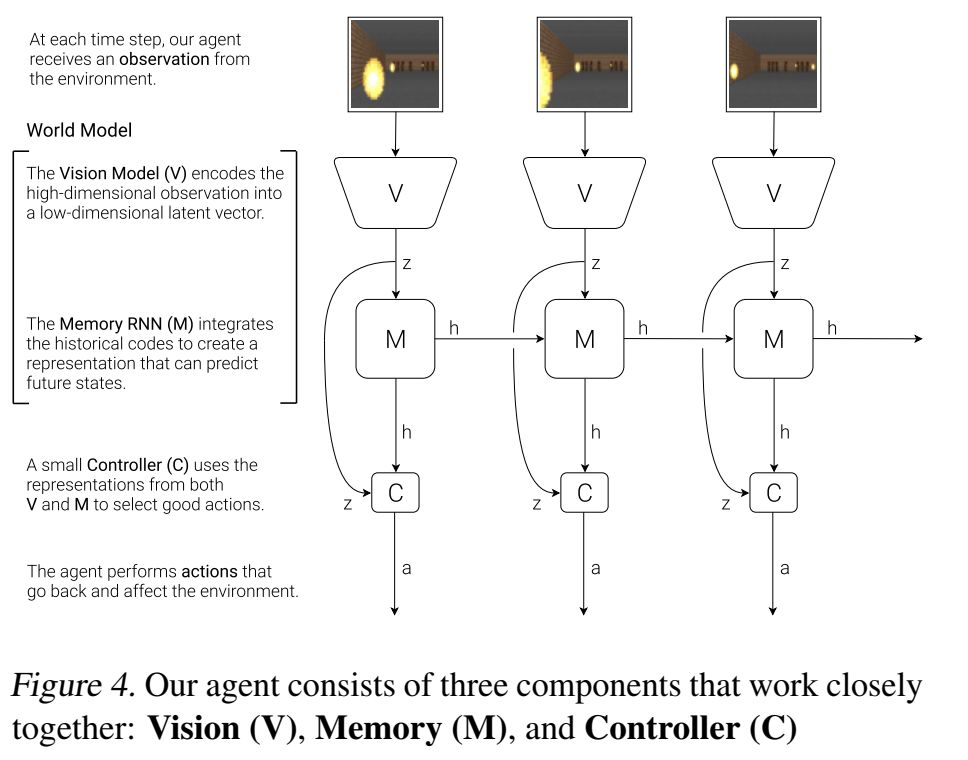
World Models
Then, we can also get inspiration from human learning, that is, direct learning. In fact, neuroscience research in the past and present directly shows that the learning of humans and animals can be represented by reinforcement learning and meta-learning.
Meta-Learning in Reinforcement Learning
Prefrontal cortex as a meta-reinforcement learning system
The results of the last paper are the same as our conclusions. Lunzhi had previously reported this: DeepMind paper: Dopamine is not only responsible for happiness, but also helps reinforcement learning. Fundamentally speaking, one can think that human wisdom is the result of the combination of reinforcement learning and meta-learning-meta-reinforcement learning. If this is the case, should we do the same with AI?
Conclusion
The classic basic flaws of reinforcement learning may limit it to solve many complex problems. As mentioned in many papers mentioned in this article, it is not necessary to use manual writing or strict rules to not adopt the method of learning from scratch. Meta-reinforcement learning allows agents to learn better through high-level guidance, experience, and cases.
The time is now ripe to start the above-mentioned work, to move our attention away from pure reinforcement learning, and to pay more attention to learning methods learned from humans. But the work for pure reinforcement learning should not be stopped immediately, but should be used as a supplement to other work. Methods based on meta-learning, zero-time learning, few-time learning, transfer learning and their combination should become the default method, and I am willing to contribute my strength to this.
Business Style Leather Phone Case
Business Style Leather Phone Case,Cover Leather Case,Flip Cover Leather Case,Genuine Leather Case
Guangzhou Jiaqi International Trade Co., Ltd , https://www.make-case.com