Speaking of artificial intelligence, the ImageNet Challenge, which gave birth to convolutional neural networks and deep learning algorithms, is probably the most famous AI data set in the world. In the past 8 years, under the training of ImageNet data set, the accuracy of artificial intelligence for image recognition has been improved by 10 times, even surpassing human vision itself.
However, scientists in the AI ​​field have not stopped their progress. Last weekend, one of the most outstanding scientists in the field of artificial intelligence: Li Feifei, a tenured professor at Stanford University and chief scientist of Google Cloud, gave us a wonderful speech called "Visual Intelligence Beyond ImageNet" at the annual meeting of the Future Forum. She told us that AI can not only accurately identify objects, but also understand the content of pictures, even write a short article based on a picture, and "understand" the video...

We all know that there are many kinds of animals on the earth, most of them have eyes, which tells us that vision is the most important way of feeling and cognition. It is vital to the survival and development of animals.
So whether we are talking about animal intelligence or machine intelligence, vision is a very important cornerstone. Among these systems that exist in the world, the one we currently understand most is the human visual system. Since the Cambrian eruption more than 500 million years ago, our visual system has continuously evolved and developed. This important process has allowed us to understand the world. Moreover, the visual system is the most complex system in our brain. The cortex responsible for visual processing in the brain accounts for 50% of all cortex. This tells us that the human visual system is very remarkable.
A cognitive psychologist has done a very famous experiment. This experiment can tell you how amazing the human visual system is. Look at this video. Your task is to raise your hand if you see a person. The presentation time of each picture is very short, that is, 1/10 second. Not only that, if you ask everyone to find someone, you don’t know what kind of person the other person is, or where the person is standing, what posture they use, and what clothes they wear. However, you can still identify this quickly and accurately people.
In 1996, the famous French psychologist and neuroscientist Simon J. Thorpe's paper proves that visual cognition is the most impressive ability in the human brain because it is very fast, about 150 milliseconds. Within 150 milliseconds, our brain can distinguish very complex images with and without animals. At that time, computers were very different from human beings. This inspired computer scientists. The most basic problem they hope to solve is the problem of image recognition.
Outside of ImageNet, what can we do beyond pure object recognition?
Twenty years later, experts in the computer field have also invented several generations of technology for object recognition. This is known as ImageNet. We have made great progress in the field of image recognition: in 8 years, in the ImageNet Challenge, the computer's error rate for image classification has been reduced by 10 times. At the same time, a huge revolution in the past 8 years has also emerged: In 2012, the emergence of convolutional neural network and GPU (Graphic Processing Unit) technologies has contributed to computer vision and artificial intelligence research. Said it is a very exciting progress. As a scientist, I am also thinking about what else can we do besides ImageNet and pure object recognition?
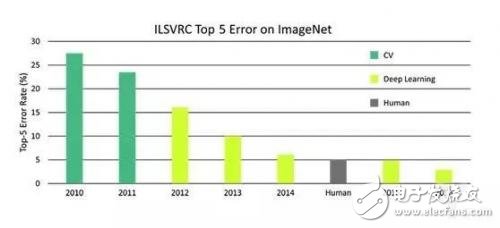
In 8 years, in the ImageNet Challenge, the computer's error rate for image classification has been reduced by 10 times.
Let me tell you through an example: two pictures contain an animal and a person. If you simply observe what appears in the two pictures, the two pictures are very similar, but the stories they present are completely different. . Of course, you definitely don't want to appear in the scene in the picture on the right.

This embodies a very important problem, that is, the most important and basic image recognition function that humans can do-understanding the relationship between objects in images. In order to simulate human beings, in the computer's image recognition task, the input is the image, and the information output by the computer includes the objects in the image, their positions and the relationship between the objects. We currently have some preliminary work, but most of the relationships between objects judged by computers are very limited.
Recently we started a new research. We use deep learning algorithms and visual language models to let the computer understand the relationship between different objects in the image.
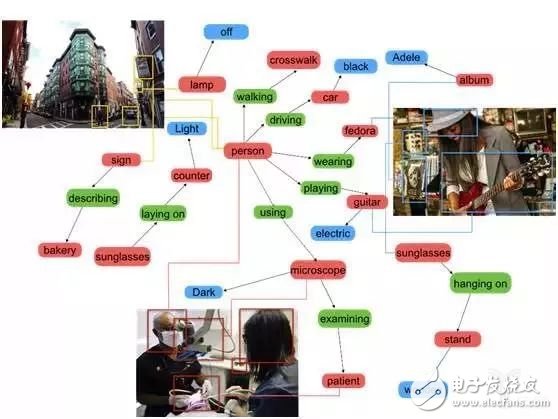
Computers can tell us the spatial relationship between different objects, compare them, observe whether they are symmetrical, and then understand the actions between them and the positional relationship between them. So this is a richer way to understand our visual world, not just simply identifying the names of a bunch of objects.

Visual RelaTIonship DetecTIon with Language Priors
What's more interesting is that we can even let the computer realize Zero short (zero sample learning) object relationship recognition. For example, use a picture of someone sitting on a chair with a fire hydrant next to the training algorithm. Then take out another picture, sitting alone on the fire hydrant. Although the algorithm has not seen this picture, it can express that it is "a person sitting on a fire hydrant". Similarly, the algorithm can recognize "a horse wearing a hat", although there are only pictures of "people riding a horse" and "people wearing a hat" in the training set.
Let AI understand imagesAfter the object recognition problem has been solved to a large extent, our next goal is to get out of the object itself and pay attention to the relationship between objects, language and so on.
ImageNet has brought us a lot, but the information it can identify from images is very limited. COCO software can recognize multiple objects in a scene and can generate a short sentence describing the scene. But the visual information data is much more than that.
After three years of research, we have discovered a richer method to describe these content, through different labels, describe these objects, including their properties, attributes and relationships, and then build them through such a map. The connection between the two, we call it Visual Genome dataset (Visual Genome dataset). This data set contains more than 100,000 images, more than 1 million attributes and relationship tags, and millions of descriptions and Q&A messages. In a data set like ours, it can very accurately allow us to go beyond object recognition to conduct more accurate research on the recognition of relationships between objects.
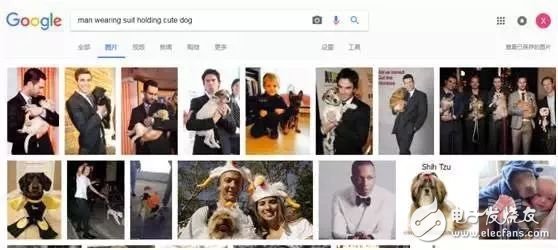
So how do we use this tool? Scene recognition is an example: it is a simple task to look at separately, such as searching for "man in suit" or "cute puppy" in Google, and you can get the desired result directly. But when you search for "a man in a suit holding a cute puppy", its performance becomes bad. This kind of relationship between objects is a difficult thing to deal with.
When searching for images, most of the algorithms of search engines may only use the information of the object itself. The algorithm simply understands what objects are in the image, but this is not enough. For example, if we search for a picture of a man sitting on a chair, if we can include all the relationships outside the object and within the scene, and then find a way to extract the precise relationship, the result will be better.
In 2015, we began to explore this new presentation method. We can enter very long descriptive paragraphs, put them into the ImageNet dataset, and then compare it with our scene graph. We use this This algorithm can help us conduct a good search, which far exceeds the results we have seen in the previous image search technology.
The accuracy of Google Images has been significantly improved
This looks great, but everyone has a question, where can I find these scene images? Constructing a scene graph is a very complicated and difficult thing. At present, the scene graphs in the Visual Genome data set are all manually defined. The entities, structures, relationships between entities and the matching of images are all done manually by us. The process is painful, and we don’t want to have to Do this work in a scene.
So our next step is to hope that there will be a technology that automatically generates scene graphs. Therefore, in a CVPR article published this summer, we made such a scheme to automatically generate scene graphs: For an input image, we first obtain the candidate results of object recognition, and then use graph inference algorithms to get the entity and the entity Relationship and so on; this process is done automatically.
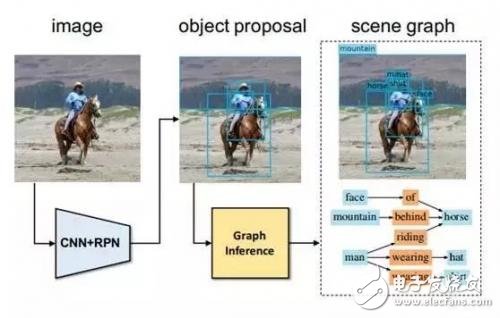
Scene Graph GeneraTIon by Iterative Message Passing
Single Phase Online Ups,Tower Ups,Rack Mount Ups,Online Dual Conversion
Shenzhen Unitronic Power System Co., Ltd , https://www.unitronicpower.com